Optimizing MySQL queries. Multiple SELECT COUNT in one MySQL C query working with mysql multiple queries at the same time
October 9, 2008 at 11:37 pmOptimizing MySQL Queries
- MySQL
In everyday work, you encounter fairly similar errors when writing queries.
In this article I would like to give examples of how NOT to write queries.
- Select all fields
SELECT * FROM tableWhen writing queries, do not use a selection of all fields - "*". List only the fields you really need. This will reduce the amount of data fetched and sent. Also, don't forget about covering indexes. Even if you actually need all the fields in the table, it is better to list them. Firstly, it improves the readability of the code. When using an asterisk, it is impossible to know which fields are in the table without looking at it. Secondly, over time, the number of columns in your table may change, and if today there are five INT columns, then in a month TEXT and BLOB fields may be added, which will slow down the selection.
- Requests in a cycle.
You need to clearly understand that SQL is a set-operating language. Sometimes programmers who are accustomed to thinking in terms of procedural languages find it difficult to shift their thinking to the language of sets. This can be done quite simply by adopting a simple rule - “never execute queries in a loop.” Examples of how this can be done:1. Samples
$news_ids = get_list("SELECT news_id FROM today_news ");
while($news_id = get_next($news_ids))
$news = get_row("SELECT title, body FROM news WHERE news_id = ". $news_id);The rule is very simple - the fewer requests, the better (although there are exceptions to this, like any rule). Don't forget about the IN() construct. The above code can be written in one query:
SELECT title, body FROM today_news INNER JOIN news USING(news_id)2. Inserts
$log = parse_log();
while($record = next($log))
query("INSERT INTO logs SET value = ". $log["value"]);!}It is much more efficient to concatenate and execute one query:
INSERT INTO logs (value) VALUES (...), (...)3. Updates
Sometimes you need to update several rows in one table. If the updated value is the same, then everything is simple:
UPDATE news SET title="test" WHERE id IN (1, 2, 3).!}If the value being changed is different for each record, then this can be done with the following query:
UPDATE news SET
title = CASE
WHEN news_id = 1 THEN "aa"
WHEN news_id = 2 THEN "bb" END
WHERE news_id IN (1, 2)Our tests show that such a request is 2-3 times faster than several separate requests.
- Performing operations on indexed fields
SELECT user_id FROM users WHERE blogs_count * 2 = $valueThis query will not use the index, even if the blogs_count column is indexed. For an index to be used, no transformations must be performed on the indexed field in the query. For such requests, move the conversion functions to another part:
SELECT user_id FROM users WHERE blogs_count = $value / 2;Similar example:
SELECT user_id FROM users WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(registered)<= 10;Will not use an index on the registered field, whereas
SELECT user_id FROM users WHERE registered >= DATE_SUB(CURRENT_DATE, INTERVAL 10 DAY);
will. - Fetching rows only to count their number
$result = mysql_query("SELECT * FROM table", $link);
$num_rows = mysql_num_rows($result);
If you need to select the number of rows that satisfy a certain condition, use SELECT query COUNT(*) FROM table, rather than selecting all rows just to count their number. - Fetching extra rows
$result = mysql_query("SELECT * FROM table1", $link);
while($row = mysql_fetch_assoc($result) && $i< 20) {
…
}
If you only need n fetch rows, use LIMIT instead of discarding the extra rows in the application. - Using ORDER BY RAND()
SELECT * FROM table ORDER BY RAND() LIMIT 1;If the table has more than 4-5 thousand rows, then ORDER BY RAND() will work very slowly. It would be much more efficient to run two queries:
If the table has an auto_increment primary key and no gaps:
$rnd = rand(1, query("SELECT MAX(id) FROM table"));
$row = query("SELECT * FROM table WHERE id = ".$rnd);Or:
$cnt = query("SELECT COUNT(*) FROM table");
$row = query("SELECT * FROM table LIMIT ".$cnt.", 1");
which, however, can also be slow if there are a very large number of rows in the table. - Usage large quantity JOIN's
SELECT
v.video_id
a.name,
g.genre
FROM
videos AS v
LEFT JOIN
link_actors_videos AS la ON la.video_id = v.video_id
LEFT JOIN
actors AS a ON a.actor_id = la.actor_id
LEFT JOIN
link_genre_video AS lg ON lg.video_id = v.video_id
LEFT JOIN
genres AS g ON g.genre_id = lg.genre_idIt must be remembered that when connecting tables one-to-many, the number of rows in the selection will increase with each next JOIN. For such cases, it is faster to split such a query into several simple ones.
- Using LIMIT
SELECT… FROM table LIMIT $start, $per_pageMany people think that such a query will return $per_page of records (usually 10-20) and therefore will work quickly. It will work quickly for the first few pages. But if the number of records is large, and you need to execute a SELECT... FROM table LIMIT 1000000, 1000020 query, then to execute such a query, MySQL will first select 1000020 records, discard the first million and return 20. This may not be fast at all. There are no trivial ways to solve the problem. Many simply limit the number of available pages to a reasonable number. You can also speed up such queries using covering indexes or third-party solutions (for example sphinx).
- Not using ON DUPLICATE KEY UPDATE
$row = query("SELECT * FROM table WHERE id=1");If($row)
query("UPDATE table SET column = column + 1 WHERE id=1")
else
query("INSERT INTO table SET column = 1, id=1");A similar construction can be replaced with one query, provided that there is a primary or unique key for the id field:
INSERT INTO table SET column = 1, id=1 ON DUPLICATE KEY UPDATE column = column + 1
I have already written about a variety of SQL queries, but it's time to talk about more complex things, for example, SQL query for selecting records from several tables.
When you and I made a selection from one table, everything was very simple:
SELECT names_of_required_fields FROM table_name WHERE selection_condition
Everything is very simple and trivial, but sampling from several tables at once It's getting a little more complicated. One difficulty is matching field names. For example, every table has a field id.
Let's look at this query:
SELECT * FROM table_1, table_2 WHERE table_1.id > table_2.user_id
Many who have not dealt with such queries will think that everything is very simple, thinking that only the table names have been added before the field names. In fact, this avoids contradictions between same names fields. However, the difficulty lies not in this, but in algorithm for such an SQL query.
The working algorithm is as follows: the first record is taken from table_1. Takes id this entry from table_1. Below is the full table table_2. And all records are added where the field value user_id less id selected entry in table_1. Thus, after the first iteration it may appear from 0 to infinite number resulting records. At the next iteration, the next table record is taken table_1. The entire table is scanned again table_2, and the sampling condition is triggered again table_1.id > table_2.user_id. All records that meet this condition are added to the result. The output can be a huge number of records, many times larger than the total size of both tables.
If you understand how it works after the first time, then it’s great, but if not, then read until you fully understand it. If you understand this, then it will be easier.
Previous SQL query, as such, is rarely used. It was just given for explanations of the algorithm for selecting from several tables. Now let's look at the more squat one SQL query. Let's say we have two tables: with goods (there is a field owner_id responsible for id product owner) and with users (there is a field id). We want one SQL query get all the records, and each one contains information about the user and his one product. The next entry contained information about the same user and his next product. When this user's products run out, move on to the next user. So we have to join two tables and get a result where each record contains information about the user and one of his products.
A similar query will replace 2 SQL queries: to select separately from the table with products and from the table with users. In addition, such a request will immediately match the user and his product.
The request itself is very simple (if you understood the previous one):
SELECT * FROM users, products WHERE users.id = products.owner_id
The algorithm here is already simple: the first record from the table is taken users. Next it is taken id and all records from the table are analyzed products, adding to the result those with owner_id equals id from the table users. Thus, in the first iteration, all goods from the first user are collected. At the second iteration, all products from the second user are collected, and so on.
As you can see, SQL queries for selecting from several tables not the simplest, but the benefits from them can be enormous, so knowing and being able to use such queries is very desirable.
In the last lesson we encountered one inconvenience. When we wanted to know who created the “bicycles” topic, we made a corresponding request:
Instead of the author's name, we received his identifier. This is understandable, because we made a query to one table - Topics, and the names of topic authors are stored in another table - Users. Therefore, having found out the identifier of the topic author, we need to make another query - to the Users table to find out his name:

SQL provides the ability to combine such queries into one by turning one of them into a subquery (nested query). So, to find out who created the topic "bicycles", we will make the following query:
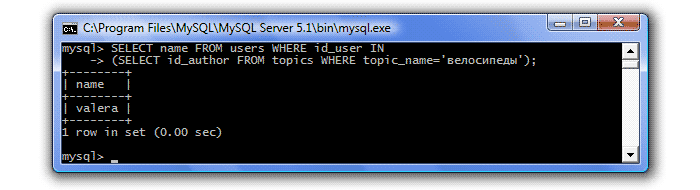
That is, after the keyword WHERE, we write another request in the condition. MySQL first processes the subquery, returns id_author=2, and this value is passed to the clause WHERE external request.
There can be several subqueries in one query, the syntax for such a query is as follows: Note that subqueries can select only one column, the values of which they will return to the outer query. Trying to select multiple columns will result in an error.
To consolidate this, let’s make another request and find out what messages the author of the “bicycles” topic left on the forum:

Now let’s complicate the task, find out in which topics the author of the “bicycles” topic left messages:

Let's figure out how it works.
- MySQL will execute the deepest query first:
- The resulting result (id_author=2) will be sent to external request, which will take the form:
- The resulting result (id_topic:4,1) will be passed to an external request, which will take the form:
- And it will give the final result (topic_name: about fishing, about fishing). Those. the author of the "bicycles" topic left messages in the "About fishing" topic created by Sergei (id=1) and in the "About fishing" topic created by Sveta (id=4).
- It is not recommended to create queries with a nesting degree greater than three. This leads to increased execution time and difficulty in understanding the code.
- The given syntax for nested queries is probably the most common, but not the only one. For example, instead of asking
write
Those. we can use any operators used with keyword WHERE (we studied them in the last lesson).