Information search in the Internet space. Search engine characteristics
1. Specifying a page address . This is the most fast way search, but it can only be used if the exact address of the document is known.
ADDRESS IS USED TO SEARCH THE NECESSARY INFORMATION ON THE NETWORK server address and file name on this server, for example:
http ://www.kazan.ru
(hierarchical structure - from right to left http - hypertext protocol, www - the site is in the Web space).
Parts of the address:
Ru - Russia (maybe three-letter)
Kazan - resource of Kazan,
Www - Internet resource, Web Site (web page), the site contains hyperlinks that allow you to navigate in the flow of information on the principle of a doll. The browser program allows you not to get lost (Home Page-main page).
Http is a hypertext transfer protocol.
In terms of protocols, the Internet uses several types of protocols that have evolved over time and advances in computer technology. These include the text-based telnet protocol, the ftp file protocol, the usenet teleconferencing protocol, the wais database protocol, the gopher protocol, and others.
2. Access to the search server (search engine). Using search engines is the most convenient way to find information.
Currently, the following search servers are popular in the Russian-speaking part of the Internet:
Search Engine Example:
www.rambler.ru
www.goo-gle.ru
The search engine finds the site address by keywords, even by phrases.
There are other search engines as well. For example, an efficient search system is implemented on the mail.ru mail service server.
Search engine query language
A group of keywords, formed according to certain rules - using the query language, is called a request to the search server. Query languages for different search engines are very similar. You can learn more about this by visiting the "Help" section of the desired search server. Consider the rules for generating queries on the example of the Yandex search engine.
| Operator syntax | What does operator mean | Request example |
| space or & | Logical AND (within sentence) | physiotherapy |
| && | Logical AND (within the document) | recipes && (melted cheese) |
| I | Logical OR | photo | photography | snimok | photographic image |
| + | Mandatory presence of the word in the found document | +to be or +not to be |
| () | Grouping words | (technology \ production) (cheese \ cottage cheese) |
| ~ | Binary operator AND NOT (within a sentence) | banks ~ law |
| ~~ or ___ | Binary AND NOT operator (within document) | Paris-jou guide ~~ (agency | tour) |
| /(nm) | Distance in words (minus (-) - back, plus (+) - forward) | suppliers /2 musical coffee /(-2 4) education vacancies - /+1 students |
| “ ” | Phrase search | "little red riding hood" Equivalently: red / +1 riding hood |
| &&/(nm) | Distance in sentences (minus (-) - back, plus (+) - forward) | bank && /1 taxes |
To get the best search results, you need to remember a few simple rules:
Don't search for information on just one keyword.
It is best not to enter keywords in capital letters, as this may result in the same words written in lower case not being found.
If your search does not return any results, check to see if there are keywords x spelling errors.
Modern search engines provide the ability to connect to the generated query of a se-mantic analyzer. With its help, you can, by entering a word, select documents in which there are derivatives of this word in various cases, tenses, etc.
The most accessible and convenient way to find information on the World Wide Web is to use search engines. At the same time, information can be searched for by catalogs, as well as by a set of keywords that characterize the searched text document.
Consider the use of search servers in more detail. The search server contains a large number of links to a variety of documents, and all these links are systematized into subject directories. For example: sports, movies, cars, games, science, etc. Moreover, these links are set by the server independently, in automatic mode by regularly viewing all Web pages that appear on the World Wide Web.
In addition, search servers provide the user with the ability to search for information by keywords. After entering the keywords, the search server starts browsing documents on other Web servers and displays links to those documents in which the specified words are found. Typically, search results are sorted in descending order by a special document rating, which shows how well a given document matches the search conditions or how often it is requested on the network.
Some important addresses:
www.kros.ru - Kazan regional educational network,
www.edu.ru - website of the Russian Ministry of Education,
www.fio.ru - Federation of Internet Education.
3. Navigation on hyperlinks. This is the least convenient method, since it can be used to search for documents that are only similar in meaning to the current document. If the current document is dedicated, for example, to music, then using the hyperlinks of this document, it will hardly be possible to get to a site dedicated to sports
There is a type of people who just love to use a lot of beautiful metaphors. These are the people who compare the World Wide Web to a dump. As if on the network everything is dumped in a big heap and the devil can break a leg there. It seems that everything is on the web, but in order to find something, you have to dig up huge mountains of garbage.
Well, that's a nice metaphor. But that doesn't mean she's right. For many people, at first glance, a huge amount of useless things are piled on the table. But for those people who work at these tables, the arrangement of things lends itself to a very definite logic. Those things that are needed most often, such as a tea mug, are at arm's length. And those things that are not always necessary are located further. And this is by no means a dump or a mess.
The Internet also has its own logic. If you know a few rules and use them when searching, then any information from the Internet will be like a mug for tea at arm's length, and the feeling that the Web is a dump will immediately disappear.
In this article, we will talk about search engines and Internet search rules.
SEARCH ENGINE DEVICE
For starters, small lyrical digression about the search engine. It is so arranged that the user sees only the interface of the system itself, that is, the search bar, and everything that is inside the system remains there.
The first component of the search engine is the so-called "spider", a search robot. What are its functions? He wanders all over the Web, browsing the Internet - pages, visiting links. And he does it all non-stop. The spider does not wander for his own pleasure. It enters absolutely all the pages that it has viewed into the search engine index. Enters them in the form of meaningful words that occur on the page.
Thus, it turns out that the index, the second component of the search engine, is a huge database, with the help of which it is possible to quickly find out on which pages on the Web the search word occurs. Information for reference - the entire volume of the index of the well-known Yandex search engine is more than eighty gigabytes.
The third component after the index is the search engine itself. Its purpose is to search the right words or phrases in the index. Remember that a search engine doesn't search the entire internet - it doesn't. Just imagine that this is true: for example, the entire volume of indexed information on Yandex is 269 gigabytes. And if there was no index after entering your query, the system would have to download and view 260 gigabytes of information. It's unrealistic. Just think how long it will take to process one single request.
Following from the fact that the search is carried out not in the entire Network, but in the index, two conclusions arise. Firstly, if the search engine did not find some information, this does not mean at all that this information is not on the Web, it is not in the index of this particular search engine. Secondly, information retrieval systems in the network differ from each other not only in the interface, but also, for example, in the index and methods of compiling it. Therefore, if you did not find the information you need in one search engine, you need to look for it in another.
The search robot that compiles the index crawls all sites in a circle and very regularly - thus, the index always correctly shows the changes that have occurred on the site. Sites that have just appeared "spider" can find on their own, hitting them on the link from other sites. Also, site authors can let the "spider" know about their site.
The last component of a search engine is its World Wide Web server, which is the face of the system. This is the interface through which users make requests and receive responses to them. The World Wide Web server is just one part of the system, and not the largest.
SEARCH LANGUAGE
In order to communicate with search engines, there is a special language and special rules. Of course, it would be just great if your question was immediately given a comprehensive answer. But right now, it's just being worked on.
First you need to highlight the keywords. It is necessary to decide which few words will more fully characterize what you are looking for and enter these particular words. You will say that this is obvious. Yes it is. But you will be surprised to know what many people enter into the search bar.
There is a good thing on Yandex called "live broadcast". This is a page where you can see the last 20 searched phrases or words. Watch this page longer and you will experience many different feelings. Some requests can be recorded in a separate book - they are so amazing. Looking at some requests, you will understand that it is definitely NOT necessary to search like this.

Usually, a huge percentage of requests do not carry any clarity: "video", "tv", "download" and so on. Requesters think that the system itself should guess what users want from it. Form a search query more clearly, and the more specific it is, the less unnecessary results the search engine will give.
Some search engines distinguish between the same queries, but starting with a capital or small letter. For example, Yandex will return a different number of search results, and Google system register is ignored.

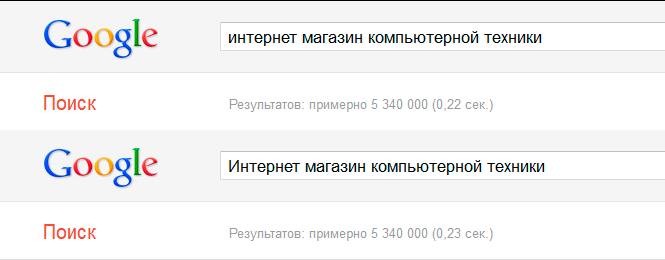
Using the "+" and "-" signs, you can either exclude words from the search or make them mandatory. In this case, there should not be a space between the sign and the word. This rule applies to all search engines.

In this request, we are looking for online stores with you computer technology, not specializing in laptops, and in the next, on the contrary, those stores that sell these same laptops.
As you can see, the search engine really gave different results.
If in your query several words are simply separated by spaces, then the search engine will look for those pages on which these words are part of one sentence. Well, if you want to find a document that contains any of the words you listed in the query, you must use the "|" sign.
Yandex gave out just a monstrous number of results, and all because now we are not looking for a specific phrase, but all results containing any of these popular words. In general, such a query is most convenient to do if there are many words of synonyms.
If you want to find stable phrases, then enter them in quotation marks. This can be applied if you, for example, are looking for lines from some literary works or quotes.
As you can see, having specified the request and instructing the search engine to search specifically for this offer, we have already received a noticeably smaller number of results.
CONCLUSION
Using all of the above methods, you can easily find the information you need. Fortunately, there are enough search engines. However, there are a huge number of tasks that search engines cannot perform.
Imagine the following situation: you urgently need the best in town System Administrator. How will you search for it? For example, you can advertise in the newspaper and then answer many phone calls for several months. Or you can come to a specialized agency and quickly find a suitable candidate there.
Similarly, with search engines - they are designed to reach as much as possible. more information. If you need to find something special, then it makes sense to use specialized search engines that search in various areas.
In conclusion, I would like to give one piece of advice. Within the framework of this article, we have given you only generalized information on compiling search queries. In fact, each search engine has its own advanced query language. Take the time to explore the possibilities of the query syntax of your favorite search engine. This will make searching much easier in the future. necessary materials. To help you links to reference materials of the two most popular search engines:
General information.
Currently, the Internet unites hundreds of millions of servers that host billions of different sites and individual files containing various kinds of information. It's a giant repository of information. There are various methods of searching for information on the Internet.
Search by known address. The required addresses are taken from directories. Knowing the address, it is enough to enter it into the address bar of the Browser.
www.gov.ru - organ server state power Russia.
Address construction by the user. Knowing the Internet address generation system, you can construct addresses when searching for Web sites.
It is necessary to add a thematic or geographical domain to a keyword (the name of a company, enterprise, organization or a simple English noun), and intuition must be connected.
Commercial Web site addresses:
www.cnn.com (CNN World News),
www.sony.com (from SONY),
www.mtv.com (MTV music news).
Addresses of educational institutions:
www.ntu.edu (US National University).
Regional server addresses:
www.poland.net (Poland),
www.israil.net (Israel).
Internet search engines
To search for information on the Internet, special information retrieval systems have been developed. Search engines have a regular address and are displayed as a Web page containing special tools for organizing search (search string, subject catalog, links). To call a search engine, just enter its address in the address bar of the Browser.
According to the method of organizing information, information retrieval systems are divided into two types: classification (rubricators) and dictionary.
Rubricators (classifiers) are search engines that use a hierarchical (tree-like) organization of information. When searching for information, the user looks through thematic headings, gradually narrowing the search field (for example, if you need to find the meaning of a word, then first you need to find a dictionary in the classifier, and then find the right word in it).
Dictionary search systems are powerful automatic software and hardware systems. With their help, information on the Internet is viewed (scanned). Data on the location of this or that information is entered into special reference books-indexes. In response to the request, a search is performed in accordance with the query string. As a result, the user is offered those addresses (URLs) where the searched word or group of words was found at the time of scanning. By selecting any of the proposed links, you can go to the found document. Most modern search engines are mixed.
The most famous and popular systems search:
www.aport.ru www.yahoo.com www.rambler.ru www.yandex.ru www.altavista.com www.google.com
There are systems that specialize in searching information resources in various directions.
Search for people on the Internet:
www.whowhere.ru www. bigfoot.com
Search by newsgroups (Usenet):
www.dejanews.com
Subject search engines:
Software search:
Search in file archives:
http://ftpseach.com city.ru, http://ftpsearch. licos.com
Catalogs (thematic collections of links with annotations):
http://www.atrus.ru
Often efficient search information can be carried out using regional catalogs - specialized servers containing data about enterprises or Web resources of a city or region. For example, for St. Petersburg, such a catalog is located at http://www.spb.ru.
A list of IPS can be found at www.monk. newmail.ru
A more detailed list of search engines and directories is presented in Table. 3.2.
Query Execution Rules
In each search engine, in the Help section, you can get information on how to search, how to compose a query string. Below is information about a typical, "average" query language.
Simple request.
Enter one word that defines the search topic. For example, in the Rambler.ru search engine, it is enough to enter: automation.
Documents are found that contain the words specified in the request. All forms of Russian words are recognized, as a rule, the case of letters is ignored.
You can use the character "*" or "?" in the query. Sign "?" in the keyword, one character is replaced, in place of which any letter can be substituted, and the character "*" is a sequence of characters.
For example, a query automaton* will find documents that include the words automatic, automatic, and so on.
Complex request.
Often there is a need to combine keywords to get more specific information. In this case, additional linking words, functions, operators, symbols, combinations of operators separated by brackets are used.
For example, the query music & (beatles | beatles) means that the user is looking for documents containing the words music and beatles or music and beatles.
Table 3.1 shows the rules for generating requests adopted in the Aport system (http://www.aport.ru).
Table 3.1
Operators for Forming Requests
| Operator | Synonyms | Comment |
| And | AND & | The query will find documents containing both keywords. It may or may not be written. For example, the query: computer science and textbook is equivalent to computer science textbook |
| OR | OR | | Searches for those documents that use either of the specified words or both words at the same time |
| NOT | NOT-~ | The search is limited to documents that do not contain the word specified after the operator |
| " " | " " | Double or single quotes allows you to find a phrase |
| date= | date: date= | The search is limited to documents that fall into specified interval dates Example 1. currency date=01/02/2002-01/03/2002. This request will return documents containing the word "currency" and having a date between February 1, 2002 and March 1, 2002. Example 2. date=01/03/2002 currency Example 3. date:<02/03/2002 валюта |
Table 3.2
List of search servers and directories
| Address | Description |
| www.excite.com | Search engine with node reviews and guides |
| www.alta-vista.com | Search server, advanced search capabilities available |
| www.hotbot.com | search server |
| www.poland.net www.israil.net | Regional search servers of Poland, Israel |
| www.ifoseek.com | Search Server (easy to use) |
| www.ipl.org | Internet Publik library, a public library operating as part of the World Village project |
| www.wisewire.com | WiseWire - organization of search using artificial intelligence |
| www.webcrawler.com | WebCrawler - search server, easy to use |
| www.yahoo.com | Web catalog and interface for accessing full-text search on the AltaVista server |
| www.aport.ru | Aport - Russian language search server |
| www.yandex.ru | Yandex - Russian-language search server |
| www.rambler.ru | Rambler - Russian-language search server |
| Internet Help Resources | |
| www.yellow.com | Internet Yellow Pages |
| monk. newmail.ru | Search engines of various profiles |
| www.top200.ru | Top 200 Websites |
| www.allru.net | |
| www.ru | Catalog of Russian Internet resources |
| www.allru.net/z09. htm | Educational Resources |
| www.students.ru | Russian student server |
| www.cdo.ru/index_new. asp | Distance Learning Center |
| www.open. ac. UK | Open University UK |
| www.ntu.edu | US National University |
| www.translate.ru | Electronic text translator |
| www.pomorsu.ru/guide. library.html | List of links to net libraries |
| www.elibrary.ru | Scientific electronic library |
| www.citforum.ru | E-library |
| www.infamed.com/psy | Psychological tests |
| www.pokoleniye.ru | Internet Education Federation website |
| www.method. people.ru | Educational Resources |
| www.spb. www.osi.ru/ic/distant | Distance learning on the Internet |
| www.examen.ru | Exams and tests |
| www.kbsu.ru/~book/ | Computer science textbook |
| Mega. km.ru | Encyclopedias and dictionaries |
Searching for information on the Internet: pitfalls
Problems that do not lie on the surface often make themselves felt only "in retrospect", after a certain stage of prospecting work has been completed and, perhaps, based on its results, some decision has already been made. What prevents making the situation transparent from the very beginning of the operation of this or that information retrieval system (IPS)? The answer is quite simple: the lack of comprehensive information of this kind on the part of the developer. The direct consequence of this is the unreliability of the received data and their uncontrolled loss. It is rare to find a search engine on the Web that does not have some "undocumented" features. It would seem that the user does not need so much information, namely:
how the IPS database is filled and what is its volume;
full range of possibilities of the search language of the system;
the main features of the presentation of search results, primarily the algorithm for ranking records from the list of responses to a search query.
Alas, the source of such information is usually not a document available from the main page of the search server, but publications of individual authors scattered over the Web, books and computer magazines. The reasons for this state of affairs, apparently, include not only the negligence of the developer, but also a factor called marketing policy. Simply put, providing the search engine with the most complete information about itself does not always have a positive effect on its ranking. Nevertheless, in some cases, the user is quite capable of taking the situation under control. It is often possible to find out the features of the selected search service with the help of testing. Building special test queries that quickly clarify exactly that aspect of the system's operation that is most important for the current task turns out to be non-trivial in many cases. How to avoid some of the troubles when working with IPS, we will devote our discussion. As examples illustrating the presentation, widely known Internet search engines will be considered.
Searching for information on the Internet
Searching for information on the Internet
To search for information in commonly used three ways(See Fig.1). The first of them - search by address. It is used when the user knows the address of an information resource containing the information he needs. When organizing the search for information by address (the form of the address - IP, domain or URL - in this case does not matter), the user simply needs to enter the address of the resource in the appropriate field of the browser - a program designed to provide access to network resources.
Rice. 1. Ways to search for information in hypertext databases
Second- search using hyperlink navigation. When using this type of search, the user must first access the server associated with the corresponding database. You can then find the document using hyperlinks. Obviously, this method is convenient when the address of the resource is unknown to the user. To be used as a starting point for searching when implementing this method, Web portals are intended - servers that provide direct access to a certain set of servers, including information resources installed on them, as well as Web applications that implement Web services corresponding to the purpose of the portal. Servers accessible through the portal may refer to a specific system (for example, corporate) or different systems and be specially selected according to the specific, thematic or other features of the documents and data contained on their sites. Typically, portals combine a variety of functions in order to keep the client as long as possible. The dominant service of the portal is the reference service: search, rubricators, financial indices, weather information, etc. While Web sites are mostly collections of static Web pages, portals are collections of software tools and pre-unstructured information that these tools turn into structured data at the request of specific users.
Third the search method involves the use of Internet search servers. Search servers are dedicated hosts - computers that host databases of Internet resources. The user interface of such a server has a field for entering keywords that describe the topic of interest to the user (See Fig. 2).

Fig.2. View of the Yandex search server window
The server perceives these words as an information request, in accordance with which it searches for resources and presents a list of found documents to the user. Obviously, when implementing this method, errors of both the 1st (missing the target) and the 2nd kind (information noise) are possible. It should be mentioned that two groups of search servers are distinguished: search engines and subject directories. Their difference is due to the method of creation and subsequent replenishment of the database of Internet resources, which this server performs information retrieval. So, search engines have in their composition a special program - a search robot. It constantly monitors the network, collects information from Web pages, indexes them and fixes their search image in its database. In subject catalogs, a database of Internet documents is formed "manually" by specialist editors. Since there is no single administration on the Internet, its information resources are constantly changing. New documents can appear in it and existing documents can disappear. The frequency of updating information in documents for different sites is different: for some it is several times per hour, for some it is once a day, day, month, etc. Therefore, it is very important to understand that when using information retrieval systems to find information on the Internet, the search is carried out not in the real space of the Web documents, but in some model, the content of which may differ significantly from the actual content of the Internet at the time of the search. According to the degree of coverage of indexed resources, search engines can be divided into two groups: international and Russian-language. The former index all documents published on the Internet in a row. The second indexes resources located in domain zones with a predominance of the Russian language. The list of the most popular systems is given in Table. one.
Tab. 1. Most Popular Search Engines
| International | Russian speakers |
|---|---|
| Yandex (44.4% of Runet) | |
| Yahoo! | Rambler (10.6% of Runet) |
| Bing | Mail.ru (7.3% of Runet) |
| msn | Nigma (0.5% Runet) |
| AltaVista | Gogo.ru (0.3% Runet) |
| Ask | Aport (0.2% Runet) |
Note: Runet is the Russian-speaking part of the Internet, which makes up domains with names ru and rf.
It should be mentioned that there is a special category of search engines - metasearch engines. Their fundamental difference from search engines and subject catalogs is that they do not have their own index database, and therefore, upon receiving a user request, they redirect it to several search servers at once (See Fig. 3).

Rice. 3. The scheme of the metasearch system
The ability to simultaneously use multiple search engines for a single request is an obvious advantage of metasearch engines. At present, the Metabot.ru system has found wide application, the interface of which is shown in Fig. 4. This system allows you to use both international and Russian-language search servers to search for resources.

Effective search for information using a computer is an urgent task that arises not only for beginners, but also for experienced Internet users, because whoever owns the data owns the world, as the well-known saying goes. Today we will analyze ways to quickly find the necessary and important information on the Russian-speaking Internet. At the moment, there are only three types:
- Searching for information via a direct link on the web
- Search using internet surfing
- Rules for searching for information on the Internet
- by indicating the direct address of the site where the necessary data and necessary information are located;
- surfing the links using a personal computer on the Internet;
- using search engines (machines) on the Internet.
Let us consider in more detail all the ways to search for up-to-date information on the network using a computer.
Searching for information via a direct link on the web
If you already know at what address on the Internet the information you need is located, then searching using a computer is noticeably easier: just enter the site address into the browser line and familiarize yourself with the proposed data. If you have opened a large text on a website page on the Internet, and you are interested in just a few lines hidden in a “ton” of printed characters, then you can use the in-page search. To do this, press the key combination Ctrl and F (of any computer keyboard layout), and in the proposed “Find” column, type in the phrase or word that is exactly contained in the paragraph with the information you are looking for, and then press “Enter”.
The browser will highlight in a different color all the words mentioned on the page that are similar to the word you are looking for. However, it often happens that we do not remember or do not know the links with the location of information on the Internet. In this case, it is most convenient to resort to the other two types of data search using a computer.
Search using internet surfing
Internet surfing is a search in which a sequential transition is made through links from one thematic site to another until the source of the necessary data is found. The advantage of this method of Internet search for data lies in its fascination and the ability to master a large amount of information from different sites consistently and thoroughly. Among the disadvantages of this type of search is its duration, as well as the fact that you also need to somehow get to the original site from which you start surfing. And if you do not have the address of the site from which you will start surfing, then here you will have to resort to the help of such a search method as search engines.

Ways to find information on the web using search engines
Today, such search engines as Yandex.ru, Rambler.ru, Google.ru are widely known to the Runet public. These sites allow you to search for data on the input query on all Internet sites. According to the principle of operation, search engines are of two types: search indexes and search directories:
- search directories. These sites provide assistance in searching for data on a specific topic on the Internet: the information in such catalogs is clearly structured into groups and topics, which helps to quickly find the result. In each topic, the user is offered a number of links to sites where you can find the knowledge of interest to him.
- Search indexes. These are pointer sites in which, when entering a keyword in the search bar, the user receives a series of links to pages on the Internet that contain the requested word or phrase. Search indexes perform searches using special programs called "spiders" that scan the pages of sites on the Internet for their topics. After such a scan, the search engine enters them into its database, from which information is later “gotten” when the user enters a request in the search period.
Rules for searching for information on the Internet

Now let's consider the basic, but important rules for effectively searching for up-to-date information on the Russian-language Internet using a computer.
- Form the correct key phrase to address the search engine. You can't use only one search word if you want to get really useful results, and you shouldn't enter too large phrases either. The optimal search query size is 2 to 4 words. If the search engine found too few results in the search results, then you should try to reformulate the entered phrase, replacing some words with synonyms, and also check for spelling errors in the words. Remember: there is no such information that is not on the Internet. Just choose the right words, follow the rules and you will find what you are looking for.
- Use special operators. A modern, efficient and fast search for any necessary information through a search engine and using a personal computer implies the knowledge and application of some tricks, which are abbreviations and special operator characters. Operators are icons used when forming a query in a search engine and making it easier to find the necessary data. Consider the most common operators and their meanings, which may be useful in practice.
- A space or sign & - means that you want to search for documents with the required phrase within one sentence. An example of entering into the search bar: delicious recipe or tasty & recipe.
- && - means the need to search for a page on which individual words from the phrase will be mentioned within the entire text, and not just one sentence. Example: delicious && recipe.
- | - you will be offered articles within which only 1 of the entered words will be used. Example: marriage | disadvantage | defect.
- + - means searching for text with a mandatory combination of consecutive words entered between the "+" sign. Example: delicious + recipe.
- “ ” – search for a chain of words without breaking it into separate words. Example: “Krasnaya Polyana sweets”.
By following these simple rules when searching for data using a computer and the Internet, you will make it easier for yourself and you can always quickly find the information you need at any time.